

As Histórias que os Bugs Contam
Realizando uma Análise Profunda em Defeitos

Supondo que não haja subnotificação de defeitos em um projeto de desenvolvimento de software (mais sobre subnotificação em um artigo futuro), normalmente olhamos para um bug como portador meramente da informação de um ponto de falha funcional ou técnico, falha esta que precisa ser evitada através do endereçamento do defeito subjacente. Em outras palavras: na maior parte das vezes, percebemos o registro de um bug apenas como um alerta de algo que precisa ser ajustado na solução de software sendo desenvolvida.
Mas os bugs contam histórias que pouca gente ouve. E ouvi-las pode fazer toda a diferença.
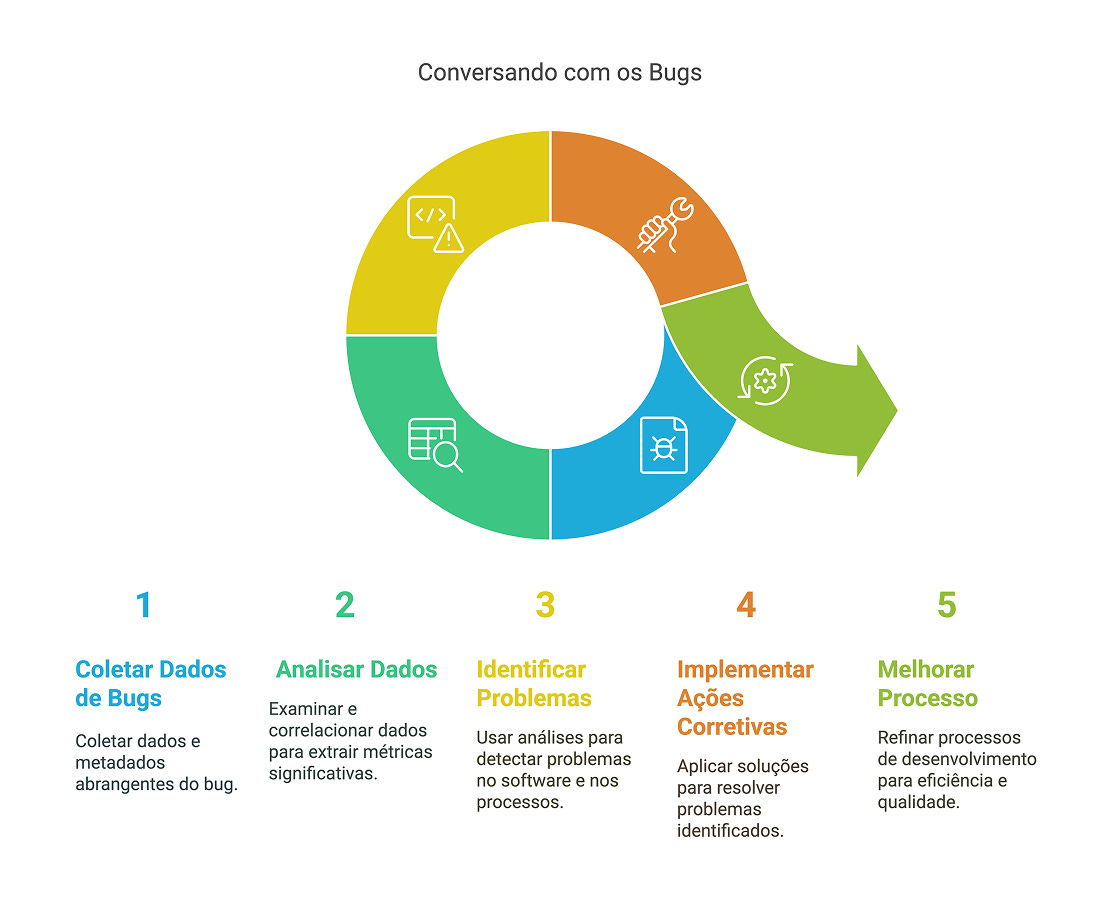
Um bug bem reportado contém dados e metadados. Os dados são as informações acerca da falha observada em si: o que aconteceu, como aconteceu, quais são as evidências e qual é a funcionalidade ou o requisito atingido. Apenas olhando para os dados do bug, podemos já derivar métricas importantes, como, por exemplo:
Densidade de defeitos por funcionalidade: quantos defeitos foram observados em uma determinada funcionalidade, o que é um indicador muito útil para o aprimoramento contínuo de cobertura de testes.
Densidade de defeitos por requisito: quais requisitos são mais atingidos, o que também contribui para a melhoria da cobertura funcional e não-funcional dos testes sendo executados.
Caminhos não mapeados: defeitos podem indicar que um caminho específico na aplicação apresenta problemas, contribuindo para o aprimoramento da solução, seja através da revisão das consequências observadas, seja através da revisão do caminho em si, seja até mesmo através do bloqueio do caminho.
Estas já são métricas muito úteis, mas existem outras, mais profundas, que advêm da análise dos metadados dos bugs:
Causa-raiz: qual foi a falha metodológica, processual ou técnica que causou o bug. Este indicador é importantíssimo e pode orientar inclusive mudanças em cultura de desenvolvimento, em ferramentas utilizadas, em identificação de treinamentos necessários, em melhoria de processos de comunicação, em ajuste de documentação, em refinamento da gestão de ambientes etc.
Índice de retrabalho: mede se este bug é um retrabalho de segunda ordem (ver meu artigo sobre o custo de defeitos) e habilita o levantamento do percentual de retrabalho sobre o total de defeitos, que deve ser uma medida a ser continuamente melhorada. Em particular, o cruzamento da métrica de índice de retrabalho com a métrica de causa-raiz pode identificar o que precisa ser ajustado mais urgentemente no projeto.
Fase de detecção do bug: pode indicar necessidade de melhoria de cobertura de testes (por exemplo, para bugs descobertos em produção) ou do reforço de testes unitários ou locais (por exemplo, para bugs descobertos em análises estáticas).
Ambiente de detecção do bug: apoia a gestão de ambientes; em particular, pode indicar que o processo e/ou periodicidade de provisionamento de ambientes precisam ser revistos.
Índice de não-bugs: percentual de bugs reportados que, na verdade, são melhorias ou, até mesmo, são falhas de interpretação de resultados de testes. Este índice pode indicar a necessidade de melhoria de conhecimento funcional, a necessidade de ajuste de resultados esperados e, até mesmo, pode apontar para a necessidade de maior envolvimento dos profissionais de Qualidade em refinamento, design e prototipação.
Listei acima apenas algumas das informações que podemos extrair de bugs. Havendo uma boa massa de dados de defeitos, a análise consolidada desses indicadores pode até mesmo alterar prazos, recursos e processos. Vou além: a análise de dados e metadados de um número considerável de defeitos de um projeto pode e deve ser utilizada como ferramenta de planejamento estratégico.
Os bugs são narrativas que, quando decifradas, oferecem valiosas lições.