

Boas métricas para uma boa gestão de fluxo
Você está medindo o que importa ou apenas colecionando números bonitos?

Na gestão de fluxo, medir é aprender sobre o sistema, não vigiar pessoas. Boas métricas expõem gargalos, variabilidade e capacidade, sustentando decisões com menos opinião e mais evidência.
Quando falamos em métricas no contexto ágil, é comum encontrar dois extremos: de um lado, organizações que medem tudo compulsivamente, gerando dashboards vistosos mas sem real impacto; de outro, times que rejeitam qualquer forma de medição, por considerá-la um resquício de controle excessivo. Nenhum desses extremos ajuda.
Métricas de fluxo, quando bem aplicadas, cumprem um papel essencial: fornecer visibilidade, apoiar decisões e promover melhorias contínuas. Elas não existem para controlar pessoas, mas para revelar padrões, gargalos e oportunidades de evolução no sistema de trabalho.
Por outro lado, mal utilizadas, métricas podem se transformar em armadilhas de vaidade, incentivando comparações improdutivas ou pressionando equipes a “jogar com os números” ao invés de gerar valor real.
O objetivo não é mostrar como medir por medir, mas como transformar métricas em guias confiáveis para uma gestão de fluxo saudável, onde a eficiência encontra o valor entregue ao cliente.

1) Lead Time (tempo entre pedido e entrega)
Antes de falarmos de Lead Time, é importante lembrarmos que na literatura e comunidade ágil encontramos conceitos e definições diferentes sobre a métrica, alguns irão sugerir que é o tempo total de navegação do item no fluxo, de sua criação até entrega. Outros ainda dirão que é o tempo de desenvolvimento. Ressalto aqui, que independente da sua interpretação sobre o Lead Time, o importante é que o conceito escolhido esteja claro e comum ao seu contexto. O conceito que estou adotando aqui é de que o Lead time navega do ponto de compromisso até sua entrega.
O que é:
Tempo total do ponto de vista de execução: Ponto de Compromisso até a entrega.
Por que importa
É a métrica da experiência. Responde “Quando fica pronto?” com base em dados históricos, não palpites.
Como medir
Carimbe duas datas por item: compromisso (quando entra no fluxo comprometido) e entrega. Meça o percentual (P50, P85, P95) e não apenas a média. Em Kanban, use isso para definir seu SLE — Service Level Expectation (ex.: “85% dos itens em até 12 dias”).
Visualização recomendada
Histograma do lead time (forma e cauda indicam variabilidade).
Scatterplot (cada ponto = um item; facilita ver tendências recentes).
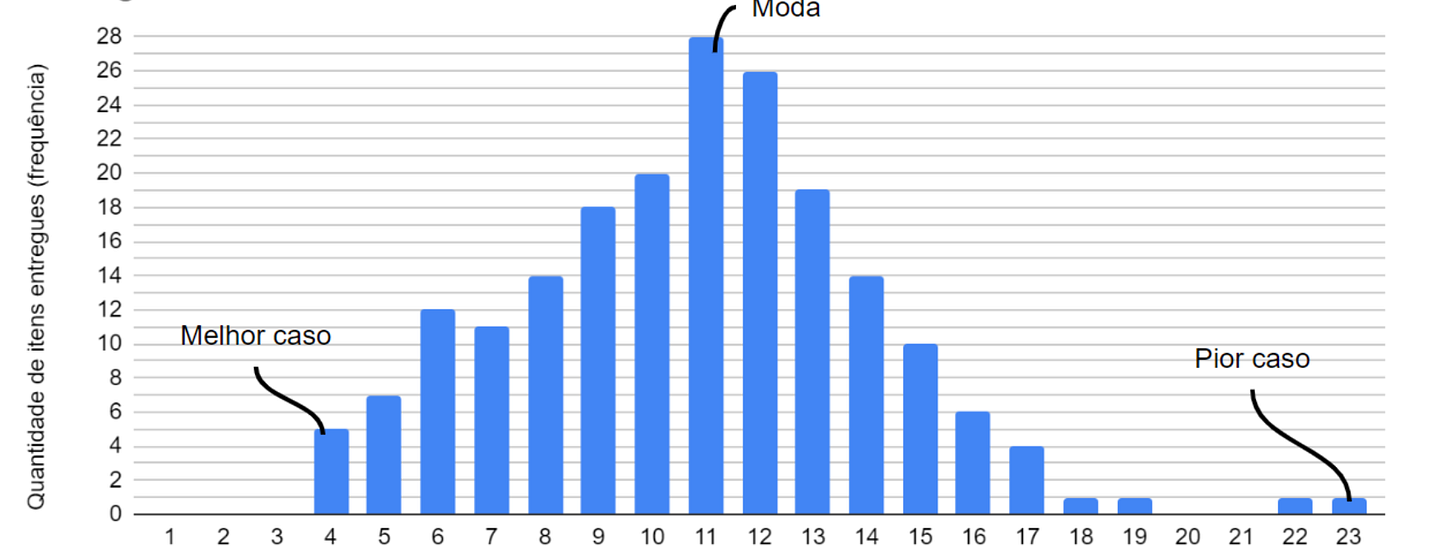
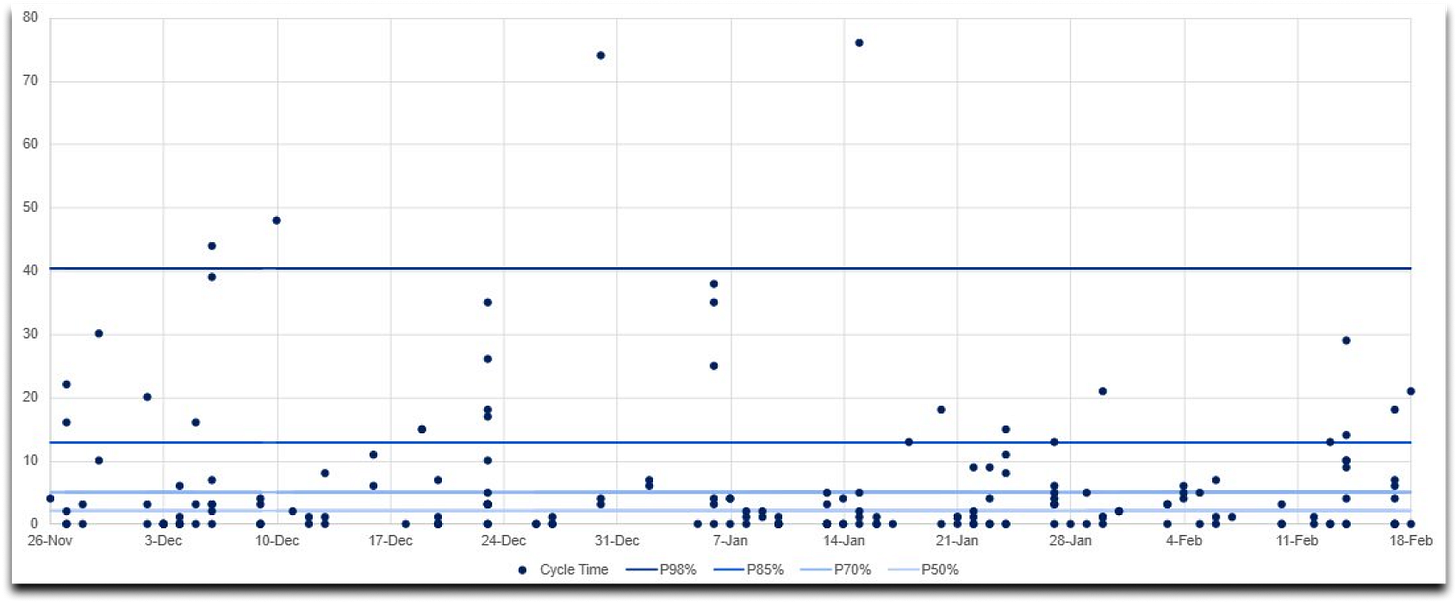
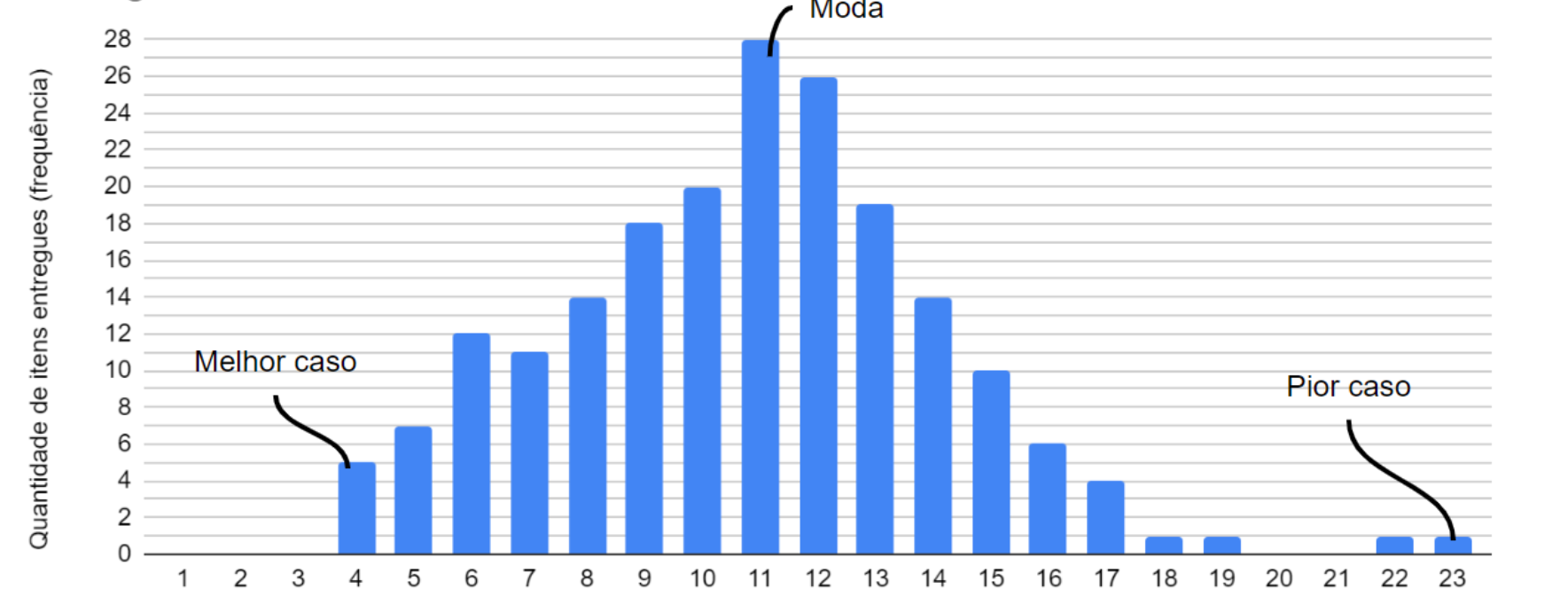
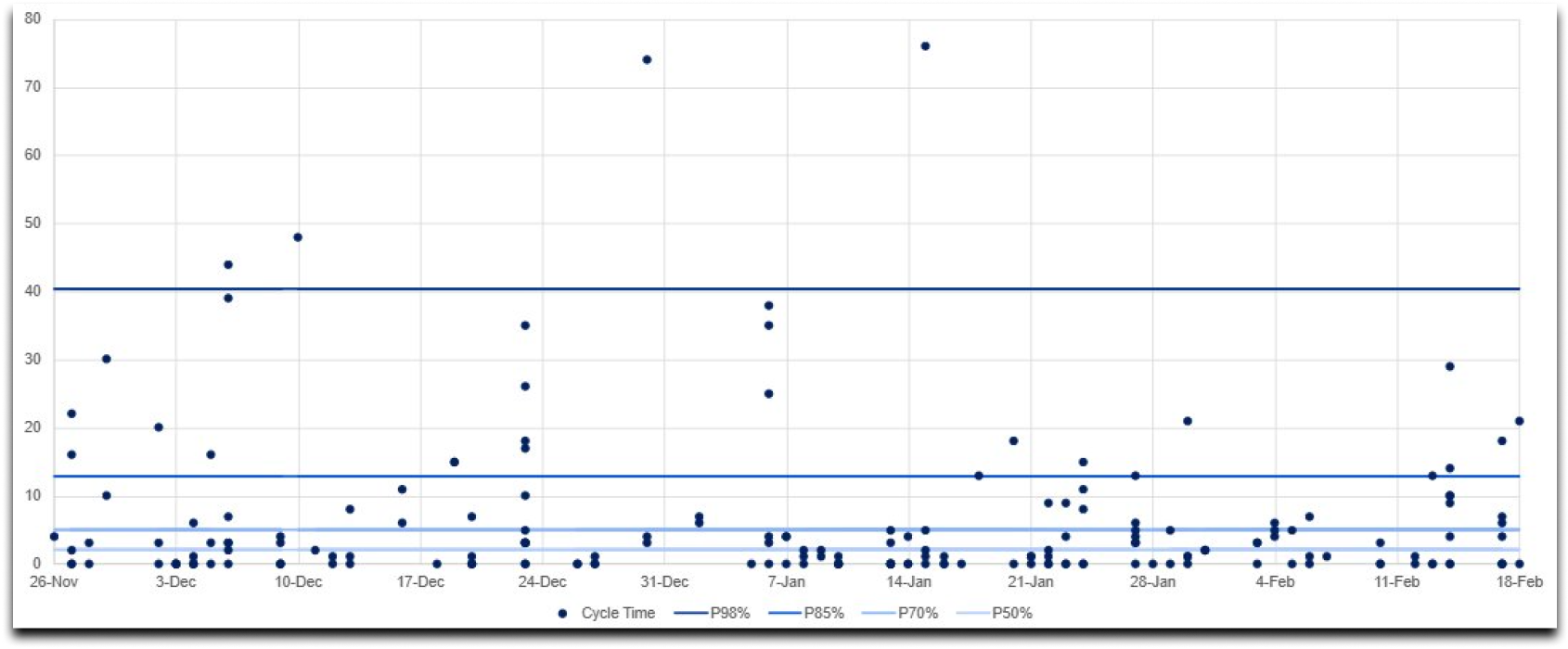
Exemplo
Seu time historicamente entrega 85% dos itens em até 12 dias. Para um novo pedido, comunique: “Comprometemo-nos com 12 dias com 85% de confiança”. Se a cauda da distribuição crescer, investigue gargalos, comunique os riscos e motivos possíveis.
Riscos comuns
– Otimizar só a média, ignorando caudas longas.
– Reduzir lead time sacrificando qualidade (retrabalho volta pelo lado).
Leituras recomendadas:
Vacanti (“When Will It Be Done?”), Anderson & Bozheva (KMM).
2) Throughput (itens concluídos por período)
O que é
Quantidade de itens terminados por período de tempo (semana/sprint/mês).
Por que importa
Reflete a capacidade observada do sistema; base para previsões probabilísticas (ex.: simulações tipo Monte Carlo).
Como medir
Conte entregas feitas por período. Use médias móveis e distribuições (P50/P85).
Visualização recomendada
Série temporal (entregas/semana).
Histograma (variabilidade do throughput).
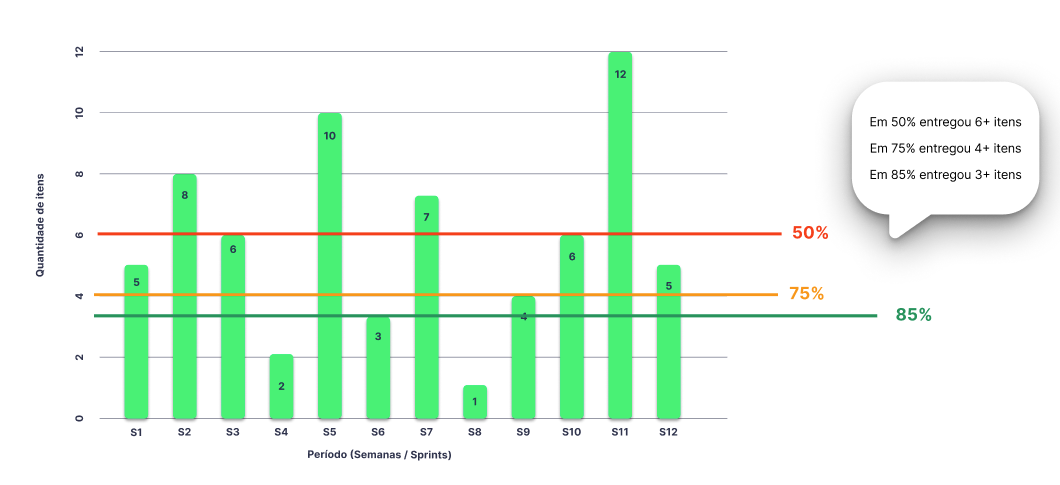
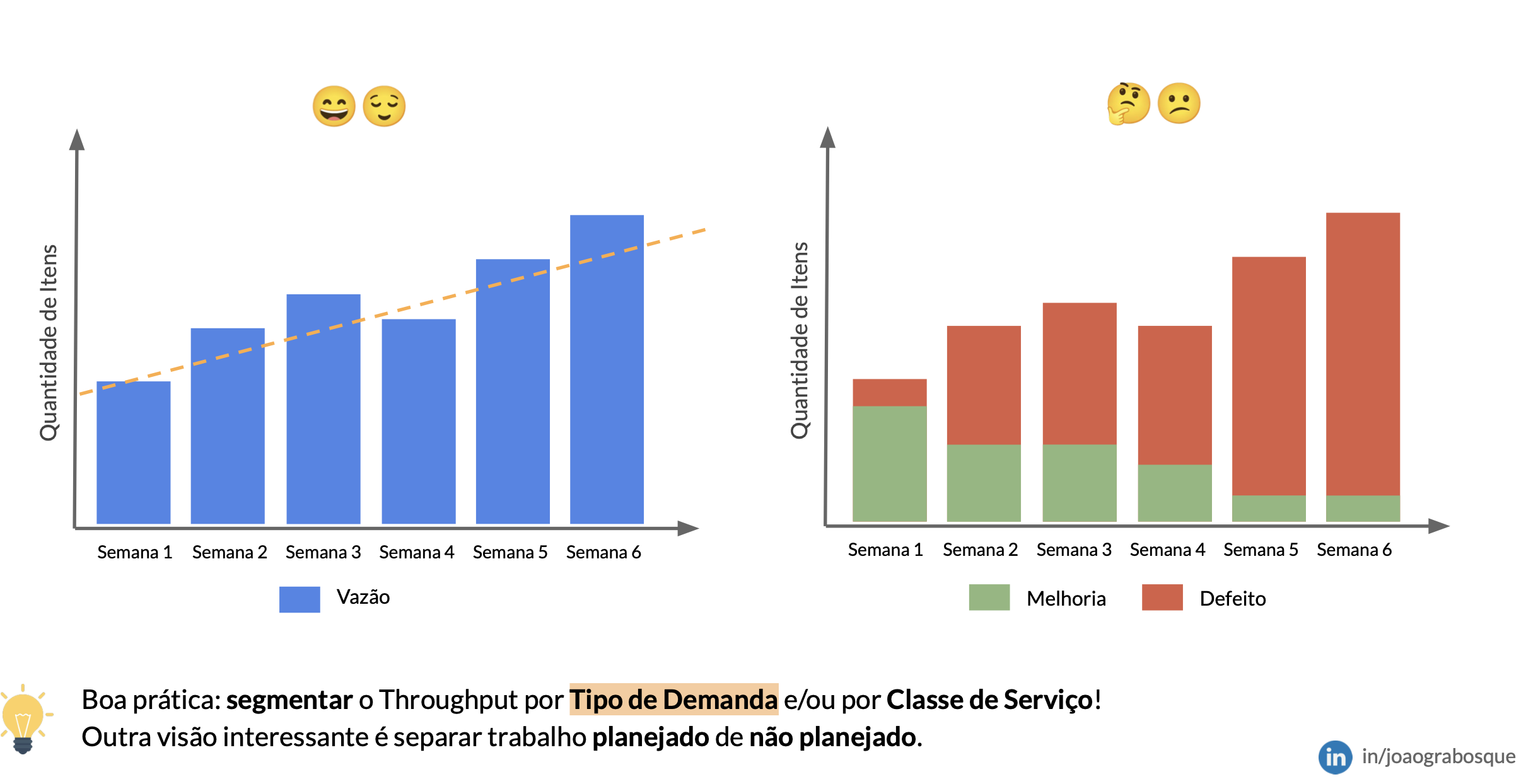
Imagem acima criada por meu amigo, João Grabosque (referência em métricas de agilidade) que demonstra o Throughput em real valor por tipo de entrega e sua qualidade.
Exemplo prático
Seu histórico mostra 7–10 itens por sprint (P85 = 10). Para planejar o trimestre, use faixas (“Entre 21 e 30 itens em 3 sprints, 85% de confiança”). Evite compromisso em número único.
Riscos comuns
– Transformar throughput em ranking de produtividade (times inflando “torradas” sem valor).
– Misturar itens muito heterogêneos sem classificar por tipo de trabalho (bugs, features, dívidas).
Leituras
Magennis (Forecasting Agile), Maccherone (Agile Metrics).
3) WIP – Work in Progress (trabalho em progresso)
O que é
Quantidade de itens em andamento agora.
Por que importa
Conecta-se diretamente à Lei de Little:
Lead Time ≈ WIP / Throughput
Domar o WIP reduz o lead time e estabiliza o sistema.
Como medir
Conte por coluna/etapa. Defina limites explícitos (WIP limits) por etapa ou tipo de trabalho.
Visualização recomendada
Quadro Kanban com limites claros por coluna.
CFD: largura das faixas indica WIP por etapa.
")
")
Vídeo que demonstra na prática o comportamento de um fluxo de limita o WIP.
Exemplo prático
Com WIP de 20 itens, o lead time mediano é 40 dias. Ao limitar WIP para 12 e implantar políticas de bloqueio/resolução, o lead time cai para 22 dias (throughput mantido). A relação com Little fica evidente.
Riscos comuns
– Limites “decorativos” que ninguém respeita.
– Aumentar WIP para “parecer ocupado”, degradando o fluxo.
Leituras
Anderson (“Kanban”), Reinertsen (teoria de filas).
4) CFD – Cumulative Flow Diagram (fluxo acumulado)
O que é
Gráfico que mostra, ao longo do tempo, quantos itens estão em cada etapa do fluxo (chegada → andamento → saída).
Por que importa
É a “radiografia” do sistema: estabilidade, gargalos, balanceamento entre entrada e saída ficam visíveis.
Como medir
Ferramentas como Jira, Azure DevOps, Trello, ClickUp geram CFD automaticamente se o board estiver bem configurado.
Como ler
Bandas engordando: fila crescendo (gargalo).
Distância vertical constante: WIP estável.
Declive da última banda: taxa de saída (throughput).
Divergência entre chegada e saída: entrada maior que capacidade.
![How to Read the Cumulative Flow Diagram [Infographic] | Nave](https://substackcdn.com/image/fetch/$s_!QAwy!,w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F9a2e7c09-a269-4335-b7a6-0a815fa8a53b_1521x915.jpeg "How to Read the Cumulative Flow Diagram [Infographic] | Nave")
![How to Read the Cumulative Flow Diagram [Infographic] | Nave](https://substackcdn.com/image/fetch/$s_!QAwy!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F9a2e7c09-a269-4335-b7a6-0a815fa8a53b_1521x915.jpeg "How to Read the Cumulative Flow Diagram [Infographic] | Nave")
Exemplo prático
A banda “Homologação” engorda e “Entrega” fica plana por duas semanas. Decisão: agregar capacidade de QA e criar critérios de entrada (DoR) mais objetivos. Na semana seguinte, as bandas voltam a estabilizar.
Riscos comuns
– Tratar como “gráfico bonito” sem políticas de ação.
– Mudar o board (colunas) sem versionar o processo, distorcendo histórico.
Leituras
Vacanti (CFD na prática), Anderson (Kanban), KMM (cadências de revisão de fluxo).
5) Eficiência de Fluxo (Flow Efficiency)
O que é
% do tempo em toque (trabalho ativo) sobre o tempo total.
Eficiência = Touch Time / Lead Time
Por que importa
Mostra o peso das filas/esperas no sistema. Geralmente, o gargalo está no wait time, não no esforço em si.
Como medir
Some o tempo em etapas ativas (desenvolvendo, testando) e divida pelo lead time total.
Visualização recomendada
Gráfico de barras por item/classe de serviço.
Mapa de calor por etapa (onde se espera mais).
Exemplo prático
Eficiência de 12% → muito tempo em espera (aprovações, handoffs, bloqueios). Ao reduzir filas e criar políticas de pull e SLAs de revisão, a eficiência sobe para 28%, com queda do lead time.
Riscos comuns
– Tentar “acelerar pessoas” em vez de reduzir filas.
– Microgerenciar tempo de toque (vai contra princípios ágeis).
Leituras
Reinertsen (teoria de filas, custos de alternância), Anderson.
6) Aging WIP (idade do trabalho em progresso)
O que é
Idade corrente dos itens ainda não finalizados, comparada ao seu SLE/percentis históricos.
Por que importa
É um alerta em tempo real: se um item já ultrapassa o P85 da sua classe de serviço, está em risco. Excelente para Flow Review semanal.
Como medir
Dias desde o início de trabalho até hoje (para itens não concluídos). Compare com P50/P85 históricos por tipo de item.
Visualização recomendada
Gráfico de barras (idade vs SLE).
Semáforos (verde dentro do P50, amarelo entre P50–P85, vermelho > P85).


Exemplo prático
Um item de “bug crítico” passa do P85 (3 dias). A equipe prioriza imediata remoção de bloqueio. Aging WIP é sinal, não pós-morte.
Riscos comuns
– Não separar por classe de serviço (bugs vs features).
– Ignorar dependências externas sem política de escalonamento.
Leituras
Vacanti (Aging WIP e SLE), KMM (cadências e políticas explícitas).
Implementação prática (checklist)
Defina eventos de dados no seu board (datas de compromisso/início/entrega/bloqueio).
Padronize políticas (DoR/DoD, classes de serviço, limites de WIP, critérios de bloqueio/desbloqueio).
Cadência de Flow Review semanal, quinzenal ou mensal com Aging WIP, CFD, Lead Time e throughput.
SLE explícito por classe de serviço (ex.: “85% dos bugs críticos em 3 dias”).
Forecast probabilístico (intervalos, não ponto único), com base no throughput histórico.
Qualidade primeiro (critérios de aceite, automação mínima, revisão por pares).
Aprendizado contínuo (retros de fluxo: que política mudamos? Que efeito teve?).
Por fim…
Boas métricas de fluxo não são um fim — são lentes para entender capacidade, variabilidade e qualidade. Quando o time mede bem, decide melhor. E quando decide melhor, o fluxo melhora.
Se amanhã você precisasse demonstrar a saúde do seu sistema, mostraria média… ou distribuições e percentis?
Referências
John D. C. Little – A Proof for the Queuing Formula L = λW (Lei de Little).
Don Reinertsen – The Principles of Product Development Flow.
David J. Anderson & Teodora Bozheva – Kanban Maturity Model.
David J. Anderson – Kanban.
Daniel S. Vacanti – When Will It Be Done? e Actionable Agile Metrics for Predictability.
Troy Magennis – Forecasting & Simulações (Monte Carlo) em Agile.
Larry Maccherone – Agile/DevOps Metrics & Analytics.